Constructing likelihood functions for interval-valued random variables
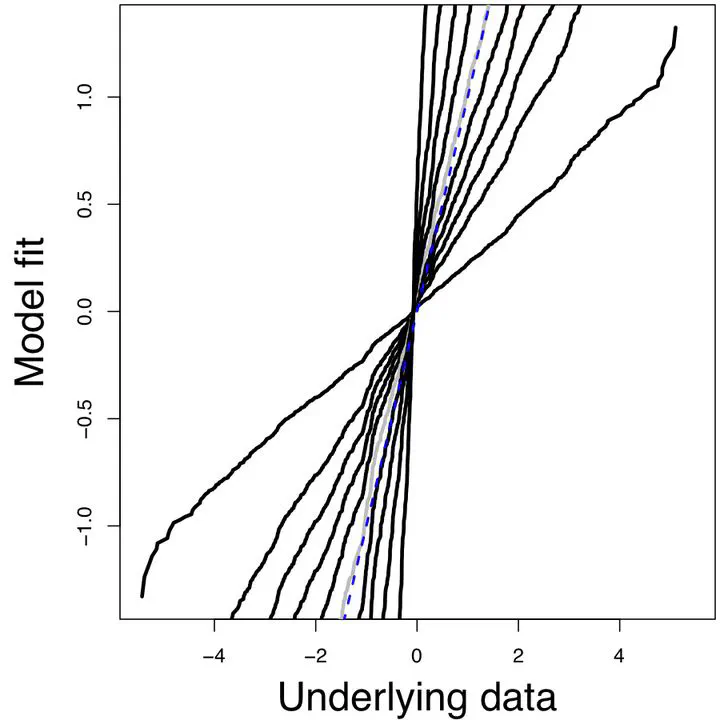 Figure 2
Figure 2Abstract
There is a growing need for flexible methods to analyse interval-valued data, which can provide efficient data representations for very large datasets. However, existing descriptive frameworks to achieve this ignore the process by which interval-valued data are typically constructed; namely by the aggregation of real-valued data generated from some underlying process. In this article we develop the foundations of likelihood based statistical inference for intervals that directly incorporates the underlying data generating procedure into the analysis. That is, it permits the direct fitting of models for the underlying real-valued data given only the interval-valued summaries. This generative approach overcomes several problems associated with existing methods, including the rarely satisfied assumption of within-interval uniformity. The new methods are illustrated by simulated and real data analyses.
Type
Publication
Scandinavian Journal of Statistics, 47(1), 1-35